Tue 17 September 2024
There's a lot of well-deserved excitement around graphics processing units (GPU), not just in the stock market but the software world too. The success stories are too good to ignore. I've heard GPUs described as an "accelerant", and one might get the impression that sprinkling a little GPU on a project will be magic pixie dust to make it go faster. It's also likely to explode if you're not careful.
There are obvious and impressive applications in graphics, gaming, simulation, statistics, deep learning - any field that requires heavy number crunching with linear algebra routines. And these are many of the hottest fields in computing at the moment for a reason.
But there is a downside for software developers.
In order to see any benefit at all from a GPU and to avoid wasting time, energy and money,
you need to keep the hardware busy with large yet simple math problems.

Not all software is amenable to this style of programming.
If not, the humble and ubiquitous CPU outperforms the GPU in many meaningful ways. But how do you know?
In this article, I'll demonstrate a workflow using matrix multiplication, perhaps the best example of a simple but time-consuming math problem. When you see a problem successfully leverage a GPU, it's a good bet matrix multiplication is involved. Or put another way, if you can express your problem as a matrix multiplication, there's a good bet GPUs will help you.
We'll generate random matrices of varying sizes, then perform multiplication using both the CPU and GPU. By timing the simplest of operations carefully, we can make some inferences about the behavior of the two processing units, and how that guides hardware decisions.
Core questions
Audience: devs faced with a decision to potentially add GPU to the mix.
-
Will a GPU make my numeric code faster, in clock time? Under all inputs?
-
How much time does the numeric code take relative to the rest of the overall process?
-
Will a GPU be economically efficient, in operations per dollar?
-
Will the burden of GPU hardware drivers and the relative scarcity of hardware itself be an issue?
If you're already deep into it or have to use it, you know this already.
Questions about why? This is a great dive into the details:
Making Deep Learning Go Brrrr From First Principles.
I'm not going to cover deep CUDA knowledge or details of how to implement various algorithms with it.
The implementation is yours. That's the point - in order to make this assessment, you need to test real code on real hardware.
Matrix math in clojure
In order to perform identical matrix multiplication operations using both the CPU and GPU,
I've chosen to use the Clojure Neanderthal library.
Why? Neanderthal allows you to write high-level code for GPU and CPU in the same language.
While not identical, the code is very similar across the platforms. This lets us translate easily
between GPU and CPU code, meaning we only have to figure the logic once.
Here are the clojure dependencies, typically found in a deps.edn file.
;; deps.edn
{:paths ["src"]
:deps {;; clojure itself is just a library
org.clojure/clojure {:mvn/version "1.12.0-alpha12"}
;; linear algebra
uncomplicate/neanderthal {:mvn/version "0.49.1"}
;; NVIDIA GPU support
uncomplicate/clojurecuda {:mvn/version "0.19.0"}
;; Intel MKL CPU support
org.bytedeco/mkl-platform-redist {:mvn/version "2024.0-1.5.10"}}}
Our clojure namespace requires the top-level APIs we'll be working with.
(ns linalg
(:require
[uncomplicate.clojurecuda.core :as cuda]
[uncomplicate.commons.core :refer [with-release]]
[uncomplicate.neanderthal.cuda :refer [cuv cuge with-default-engine with-engine]]
[uncomplicate.neanderthal.native :refer [dv dge fge]]
[uncomplicate.neanderthal.random :refer [rand-uniform! rand-normal!]]
[uncomplicate.neanderthal.core :refer [mm! zero]]))
Next, we create two n x n matrices, X and Y, and do a matrix multiplication into a pre-allocated
output matrix. Here, dge stands for Double General Matrix
(def n 1024)
(timed "cpu" n
(let [X (rand-uniform! (dge n n))
Y (rand-uniform! (dge n n))
output (zero X)]
(timed "cpu-multiply" n
(mm! 1.0 X Y output))))
And the code for the GPU. The three differences
- Note the use of
cuge (CUDA General Matrix) instead of dge.
- We need to wrap the operation in a few CUDA-specific lines to set up the engine.
- Because GPU calls are asynchronous, we need to call
syncronize to make sure we capture the actual work.
(timed "gpu" n
(cuda/with-default
(with-default-engine
(with-release [X (rand-uniform! (cuge n n))
Y (rand-uniform! (cuge n n))
output (zero X)]
(timed "gpu-multiply" n
(do
(mm! 1.0 X Y output)
(cuda/synchronize!)))))))
The timed call here is a customized version of the built-in Clojure time macro.
As clojure macros get a bit off topic, the details aren't important.
I'll just leave the code here for anyone interested.
(defmacro timed [metadata expr]
(let [sym (= (type expr) clojure.lang.Symbol)]
`(let [start# (. System (nanoTime))
return# ~expr
res# (if ~sym
(resolve '~expr)
(resolve (first '~expr)))]
(prn (str
(clojure.string/join "," ~metadata)
","
(/ (double (- (. System (nanoTime)) start#)) 1000000.0)))
return#)))
TLDR: it allows us to instrument our code and test it at various input sizes.
The macro outputs comma-separated lines like this to stdout.
gpu-mulitiply,8194,14.245
When run on both GPU and CPU for a variety of matrix sizes then plotted with a log-y axis, we can see several clear patterns. Note the y-axis is log scale.
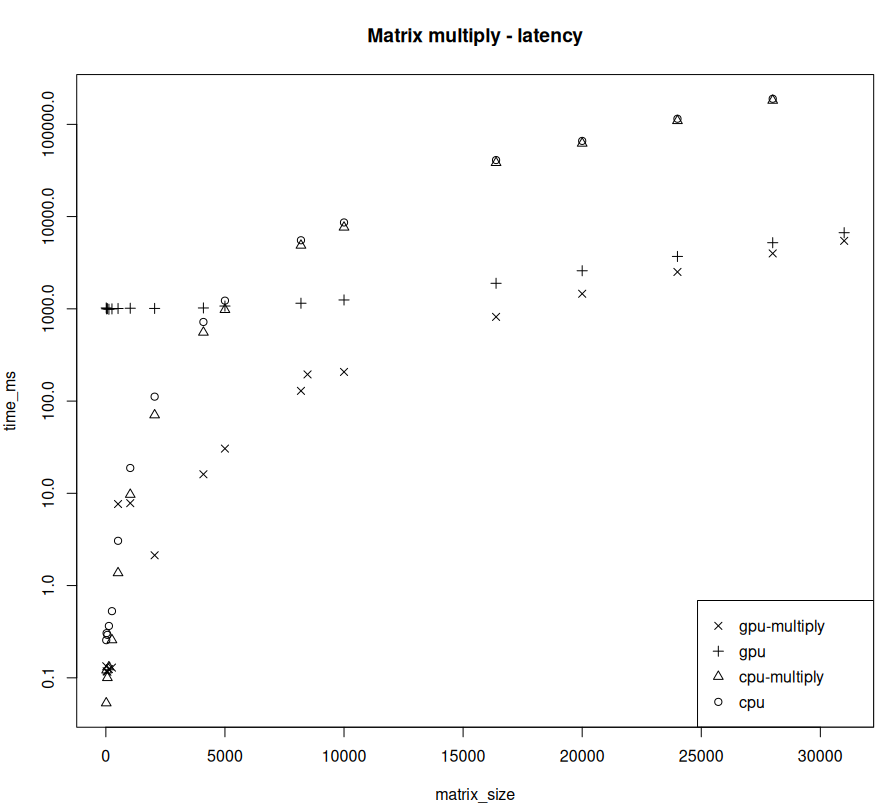
Some takeaways:
-
Below a certain size threshold, the CPU wins hands down. GPU is busy initializing, note the gap between the multiplication and the overall time. All of that time is effectively a sunk cost.
-
There is a narrow band around the threshold where the CPU and GPU are roughly equal. But the advantage changes quickly.
-
Above the threshold, the GPU is orders of magnitude faster. It's not even in the same ballpark; the speed difference is so great that it could improve processes that currently take days down to seconds. That's not just performance optimization, that's completely game changing.
So, Answer 1: GPU's advantage is highly sensitive to the amount of data you can feed it. If you can't keep it busy or rely on it for tasks that it really can't do well, you're wasting resources initializing GPU memory.

Asking a GPU to crunch a few MBs of data is like asking a container ship to mail a letter.
The rest of the process
Let's assume your number crunching code is proven to be a good match for GPU work.
Most code will still need to run in the context of a larger process. At the very least, something has to load the data into memory and onto the GPU - off of disk or network or other input streams. Then it presumably takes the result from the GPU and does the reverse - writes to disk or pushes it to the network or output streams. We are not allowed to cheat and pretend that these don't count as part of the overall cost.
Amdahl's Law provides a good description of the problem:
"the overall performance improvement gained by optimizing a single part of a system is limited by the fraction of time that the improved part is actually used"

So Answer 2: GPU optimization is only worth it if the relative gains make the overall process significantly faster.
No cheating by ignoring the non-parallelized parts.
Microeconomics of matrix math
Even if our numeric code is faster on the GPU, and even if it does speed up the process overall to make it "worth it" from a clock time perspective, how does that translate to cost?
Let's start with what we know for sure. GPUs are significantly more expensive per hour.
If your organization views data products on a cost-of-goods-sold basis, your increase in compute costs need to be offset by a decrease in processing time. A GPU may cost 20x more per hour but if you can process the same volume of data 20x faster, you break even. If you process things 100x faster, you save money! If you process the data only 4x faster, your cost per unit went up 5x and you're not going to be happy.
Or maybe cost per unit isn't relevant. Maybe you are happy spending a premium to get faster speeds, or to do things that are practically impossible on a CPU.
Either way, dollars need to enter the equation at this point.
We can scale the time by the cost/time of the average ec2 and get a similar chart with a new y axis.
Note that the shape doesn't really changed but the threshold of "worth it" moves up.
Answer 3: Depends on your willingness to pay for the decreased clock time. If it's speed at any cost, go for it! If you're constrained by efficiency, you need to normalize by the unit cost over time and adjust your threshold accordingly.
CUDAHell
So you've committed to writing code for the GPU, now comes the fun part - putting it into production.
At the very least, software teams will need access to GPU-capable development environments,
CI testing environments, and servers to deploy. Making that part of your process, if it's not already,
is a heavy lift for two reasons: expensive hardware and proprietary software drivers.
The market is tough for GPU hardware. Since it's exposed to fields like AI, gaming and cryptocurrency, demand and prices can swing wildly.
Getting adequate developer laptops is a challenge.
Then there's the software drivers.
Proprietary GPU drivers are terrible; I don't think I need to elaborate.
Installing CUDA or OpenCL on one machine is a challenge.
Installing it consistently on a fleet of developer and production machines can be a full time job.
The operational challenges of adding GPUs are significant. Those with unlimited AWS budgets and devops departments that take care of provisioning for you may not think of it as a big deal. But that's missing the point - proposing to add GPUs to your software stack is fundamentally an economic proposition, even if someone else is paying. Adding a GPU means adding complexity and costs and that needs to be justified.
Answer 4: Run through the full software dev-test-release process in a staging environment to make sure you can live with the additional operational challenges. Incorporate those as costs, again bumping up your threshold.
Review
I've outlined a rough methodology to justify using a GPU (or not) in your work.
-
Write code that works on both GPU + CPU. I realize this is easier said than done!
-
Run both on the domain of input sizes.
-
Find the performance threshold that makes it worth it for your process.
-
Find your economic threshold.
-
Adjust your developer experience, testing and release process.
We can't just assume a GPU will be a silver bullet.
All 5 of the above require a commitment of resources from your organization,
with the realization that you may need to bail out if it does not pay off.
GPUs are risky, but the potential upsides are too compelling to ignore.