Sat 01 April 2006
LIDAR data is certainly a hot technology these days. LIght Detection And Ranging data can be used to create extremely detailed terrain models but there are lots of barriers to using LIDAR data effectively. USGS Center for LIDAR Information Coordination and Knowledge was put in place to "facilitate data access, user coordination and education of lidar remote sensing for scientific needs".
Beyond the sheer size of the datasets and the knowledge and hardware required to process them, software is a big issue. In the realm of open-source GIS tools, there are many applications (GRASS being the most prominent) for dealing with elevation point data and processing it into more meaningful products such as elevation DEMs and contours.
Usually the data comes as simple ASCII text files and the x,y and z values are easily extracted from such a file. But take a look at the USGS data distribution site and you'll notice some of the datasets are distributed as LAS binary files. It makes sense to store such massive datasets in binary so I started looking for some LAS conversion tools.So after some searching, I found a bunch of proprietary products for working with LAS but no open source tools. Luckily, the format is well documented thanks to the efforts by the ASPRS to make it an open specification.
So dusting off my notes about parsing binary files in python, I set out to create a python module for extracting LIDAR data from LAS files. The LAS format contains a header which needs to be parsed first in order to read the point cloud. Once you have the header info, you can scan your way through the dataset to pick out the x,y,z values.
Here's an example of the python interface that will read the first 10,000 points into a 2D shapefile with the elevation as a attribute in the dbf:
import pylas
infile = 'sanand000001.las'
outfile = 'lidar.shp'
header = pylas.parseHeader(infile)
pylas.createShp(outfile, header, numpts=10000, rand=False)
The issue I struggled with is the sheer size of these datasets. A USGS quarter quad can contain 10 million points which is an excessive number of points to create, say, a 10 meter DEM over such a small area. Clearly there was a need to extract a subset of this dataset but just taking the points sequentially gives you a subset of the total area. So, by default, pylas randomly scans the data to pull the number of specified points so that the point cloud could cover the entire area (at a much lower point density). Without numpts specified, it will randomly select 1/2000th of the total number.
So the simplified interface to make a more manageable lidar shapefile would be:
header = pylas.parseHeader(infile)
pylas.createShp(outfile, header)
Once the shapefile is created, you can bring it into GRASS to do the processing to generate DEMs, contours and other derived elevation products:
v.in.ogr dsn=lidar.shp layer=lidar output=lidar
g.region vect=lidar
g.region res=10
v.surf.rst input=lidar elev=lidar_dem zcolumn=elev
# Launch the interactive 3D viewer
nviz lidar_dem
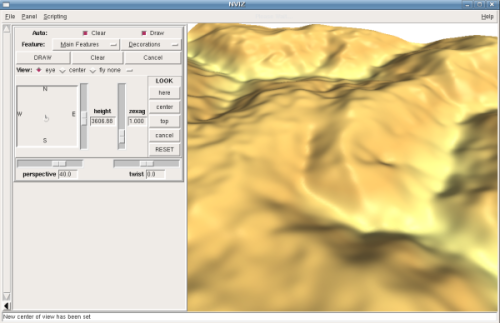
Of course the method I just described is very simplistic and does not even come close to utilizing the full potential of the LIDAR point cloud, but it's a start.
The pylas.py module can be downloaded here. The code has worked for me on the few datasets I've tested it with but it should certainly be considered a rough-cut, alpha product. There is much room for improvement and, of course, if you have any suggestions or contributions, please get in touch.